09 Breaking down programs using Procedures
This guide will show you how to break down and simplify your StarLogo TNG programs using Procedures.

You will learn
- How to program a simple wander Procedure
- How to program a flexible wander Procedure so that it can be adapted each time it is used.
What is a Procedure?
When you create a Procedure, you bundle up a set of logo blocks and give them a nick name, so that next time you want to do the same thing, instead of rebuilding the same blocks you simply use the nick name block.
In a way it is like teaching your StarLogo TNG program how to do something. For example, if you want to make toast, but don’t know how to, then you need someone to give you a simple set of instructions.
- Take out two slices of bread
- Place two slices of bread in the toaster
- Turn on the toaster
- Wait until the toast pops up
- When the toast pops up get out the butter and a knife
- Spread butter on both slices of the toast
Once you have learned how to make toast, then the next time someone wants toast, they don’t need to guide you step by step, they just say, “Please make some toast”.
In StarLogo TNG we can create a Procedure by giving a Procedure block a nick name and a set of blocks to run when it is called.
Once you have made a Procedure, you can call it from anywhere within your StarLogo TNG project and it will run.
Why use Procedures?
- They can help you make your code look simpler and easier to use.
- They mean you don’t have to keep building the same blocks over and over.
- They are flexible and can be used like templates so that they can be adapted and used differently at different times.
How to create a simple Wander Procedure
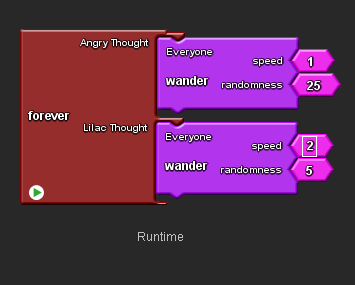
Angry Thoughts and Lilac thoughts wandering.
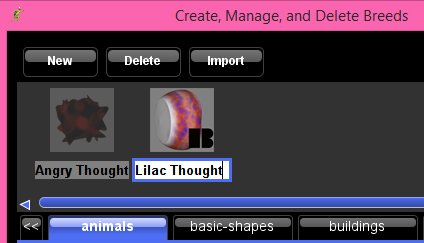
Open the Edit Breeds window and create two breeds using the Flunstella models and name them.
If you haven’t done this before, then you should read.
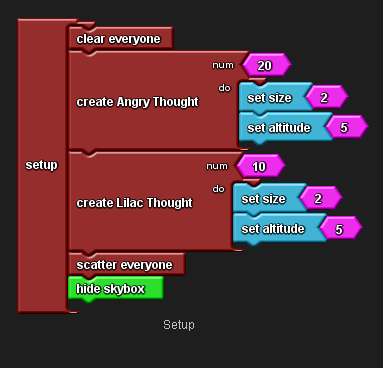
Drag the coding canvas along to the SetUp page.
Drag out a Setup block and a Clear Everyone block.
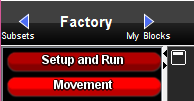
Click on the blue arrow to the right of the Factory to go to My Blocks.
Open the drawer for each of your breeds, drag out a Create Do block and place it inside the SetUp block.
Click on the left arrow to go back to the Factory.
Open the Traits drawer and drag out a Set Size block and a Set Altitude block for each breed and adjust their values.
From the Setup drawer drag out a Scatter Everyone block and place below the Create Do blocks.
From the Terrain drawer drag out a Hide Skybox block and place below the Scatter Everyone block.

Drag along to the Runtime page on the Canvas.
From the SetUp drawer drag out a Forever block and place it on the Runtime page.
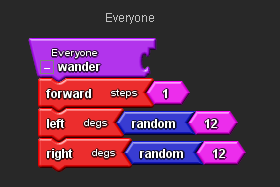
Drag along to the Everyone page on the Canvas.
Open the Procedure drawer and drag out a Procedure block, place it on the Everyone page and rename it Wander. We use this block to tell StarLogo TNG which blocks we want to put in our Procedure.
Open the Movement drawer, drag out a Forward block, a Left block and a Right block, attach them to the Procedure block as shown and adjust their values.
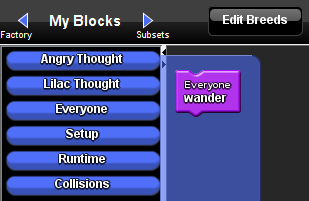
Click on the right arrow to the right of the Factory to open My Blocks.
Open the Everyone drawer, you should see a new Wander Procedure block, drag two of these out onto the Runtime page.
Procedure blocks appear in the My Blocks drawer for whichever page they were made on. Ours was made on the Everyone page so it is here. The Everyone page is a good place to store Procedures that you want all of the breeds to use, but it dosen’t really matter where Procedures go. Pages are used to help us organise our blocks, but the blocks will work wherever you put them.

Place the Wander Procedure blocks in the slots for each breed in the Runtime block.
In SpaceLand, click on the Setup block and then the Forever block to see the program run. Both breeds should wander in exactly the same way.
How to create a flexible Wander Procedure
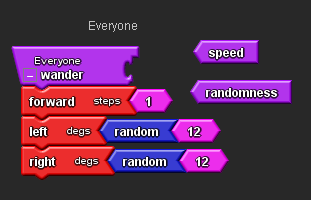
Find your Wander Procedure on the Everyone page.
From the Procedure drawer drag out two Number Param blocks and place them next to your Wander Procedure. Rename them ‘speed’ and ‘randomness’.
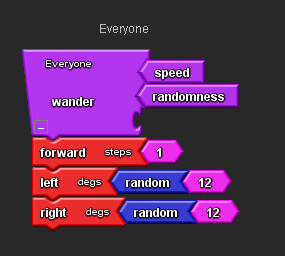
Connect them to the top of your Wander Procedure block.
Go to My Blocks and open the Everyone drawer.
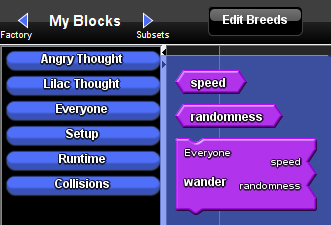
You should see two changes
- The Wander Procedure now has two slots for number blocks, one for ‘speed’ and one for ‘randomness’.
- There are now two extra blocks called Speed and Randomness.
When you use the Wander Procedure from now on, you can connect Number blocks to the slots for speed and randomness. These numbers will be sent to the Procedure so that it runs slightly differently, e.g. One breed may move two steps each time the Procedure is called, while another might move five.
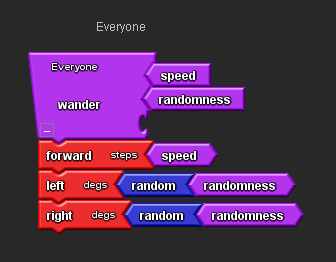
Drag the Number blocks connected to the movement blocks and put them in the bin.
Drag out one Speed block and connect it to the Forward block.
Drag out two Randomness blocks and connect them to the Random blocks.
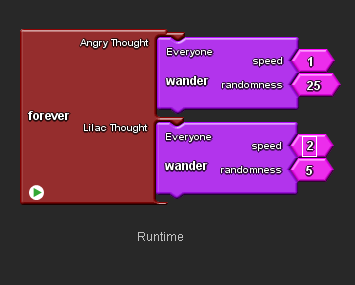
Drag along to the Runtime page.
Put the old Wander Procedures in the bin. They still work, but if you get new ones the new number slots will be named ‘speed’ and ‘randomness’ instead of ‘number param’.
Go to the Everyone drawer in the Blocks Factory and drag out new Wander Procedures and place them in the Runtime block.
From the Maths drawer drag out Number blocks to fit in the new number slots and adjust their values so that the breeds move differently. In the example shown above, the Angry Thought moves slowly and unpredictably, whilst the Lilac Thought moves more quickly and in more of a straight line.
In SpaceLand window click the Setup block and then the Forever block to test how the Procedure works.
Experiment by feeding different numbers into the Wander Procedure and see how this changes the movement of the thoughts.

You can create as many Procedures as you like, call them whenever you like and use as many Param blocks as you like, as well as passing numbers when you call a Procedure you can also pass, words, lists and boolean (1 = true, 0 = false) blocks.
You can program Procedures to call other Procedures, this can be a useful way to break your code up into lots of different modules that can be used flexibly.